
那么串口的循环队列是什么?这里以STM32的串口为例,进行解释说明。
假设串口一次只发一个数据,这倒是简单了,每次只对这一个数据进行判断,然后处理相关指令。但现实不会一直都这么美好,很多时候你收到的可能是一大串数据,你要先小心翼翼的把它们存好,然后再依次判断这里面有哪些指令要处理。

假设你定义了一个30个元素的数组a[30],每次串口收到数据都往里面存,存的时候地址加一。这个操作很简单吧,应该是都会的。
但是取的时候怎么取?你收到的指令可能是2个数据,也可能是3个数据,几种长度不一样的指令混在一起。
一次从数组里读出几个数据?怎么快速腾出已读数据的位置?还是一次都读完,然后整个数组清零?
先说一次读完,然后清零的这个方法为什么不行。
1、读的时候,里面的数据不一定是完整的。有可能某组数据刚接收到一半儿。
2、读完以后,清零之前,如果进来新的数据怎么办?
所以,比较稳妥的方法是,一次只读一个数据,读一次,清除该数据所占的位置。所以这需要一个变量,来记录数据头在这个数组中的位置。
第二,当有新数据来的时候,要知道它能放在哪,所以要有一个变量,来记录数据尾在哪。
第三,如果有必要,你可以定义一个变量来记录数据长度,存入的时候加一,取出的时候减一。
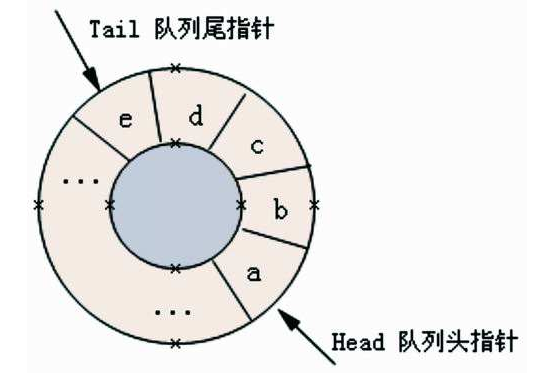
第四,也是比较重要的,如果数据尾已经是a[29]了,下一个数据放哪?整个数组都清掉?NO,假设此时a[0]~a[10]已经被取出了,数据头变成了a[11]。那么新的数据尾变成a[0],即当数据尾大于等于30的时候,变成0.
如此一来,相当于把这个数组的头和尾连了起来,成了一个封闭的环,这种处理方式,就叫做串口的循环队列。只要确保数组够大,处理速度够快,那么头和尾就不会撞上。当然,程序上也要对这种意外情况做一个处理。以下图片来自网络:
下面是代码,核心的部分都在这,复制粘贴一下,基本就可以了。
首先是定义一个结构体,关于数据头、数据尾、数组的:
typedef struct
{
u16 Head;
u16 Tail;
u16 Length;
u8 Rsv_DAT[50];
}ringbuff_t;
ringbuff_t Ringbuff;然后是结构体初始化:
void ringbuff_init(void)
{
Ringbuff.Head = 0;
Ringbuff.Tail = 0;
Ringbuff.Length = 0;
}然后是存入数据的操作,把这个函数放进串口接收中断就行:
u8 write_ringbuff(u8 data)
{
if(Ringbuff.Length >= 50)
{
return FALSE;
}
else
{
Ringbuff.Rsv_DAT[Ringbuff.Tail] = data;
Ringbuff.Tail = (Ringbuff.Tail + 1)% 50; //防止越界
Ringbuff.Length++;
return TRUE;
}
}然后是取出数据的操作:
u8 read_ringbuff(u8 *rdata)
{
if(Ringbuff.Length == 0)
{
return FALSE;
}
else
{
*rdata = Ringbuff.Rsv_DAT[Ringbuff.Head];
Ringbuff.Rsv_DAT[Ringbuff.Head] = 0;
Ringbuff.Head = (Ringbuff.Head + 1)%50;
Ringbuff.Length--;
return TRUE;
}
}然后就能用了,这是写操作:
write_ringbuff(USART_ReceiveData(USART1));
这是读操作:
read_ringbuff(&uart_buf[0]);
读操作的函数里,还可以增加一个操作,就是读出以后,把该位置数据清零,这个看个人需要。
以上,就是串口循环队列的一个简介,如果有写的不好的,欢迎留言指正。当然,方法千千万,不一定只能用这种。最后,借用流浪地球的一句经典台词作为结尾:
方法千万条,稳定第一条。
代码不规范,码农两行泪。